
- How much AI traffic is going directly to the HTML pages on my Webflow site?

- Where is that traffic coming from?
- What are those AI bots doing?
ProviderWhat It IsPurposeType.
10 days ago I set up a reverse proxy on Sygnal's site to log all AI traffic it could identify.
I launched that on Oct 13, 2025, curious if anything might show up.
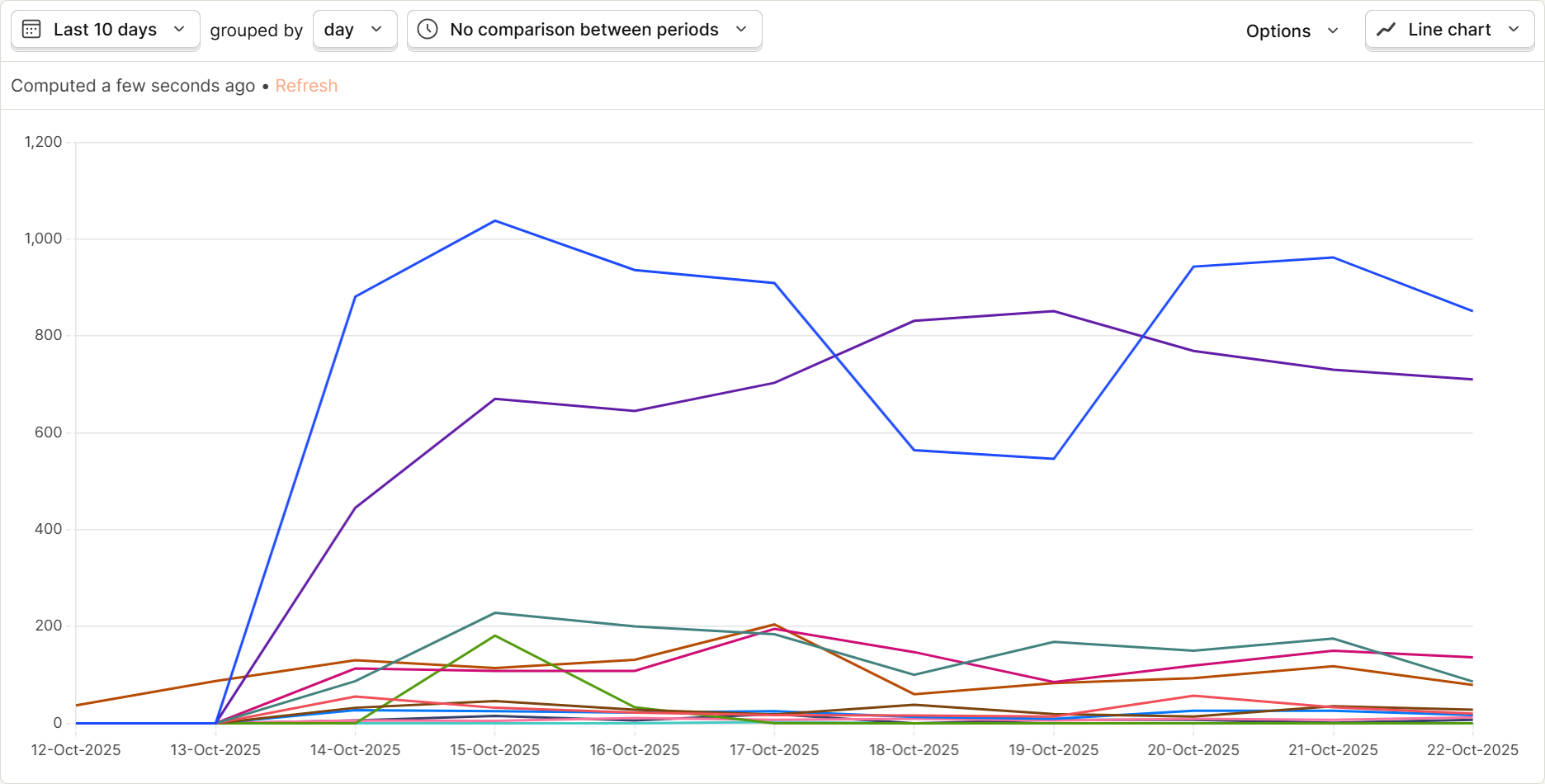
And show up, it did. How much AI traffic is going directly to the HTML pages on my Webflow site? Far more than I expected.
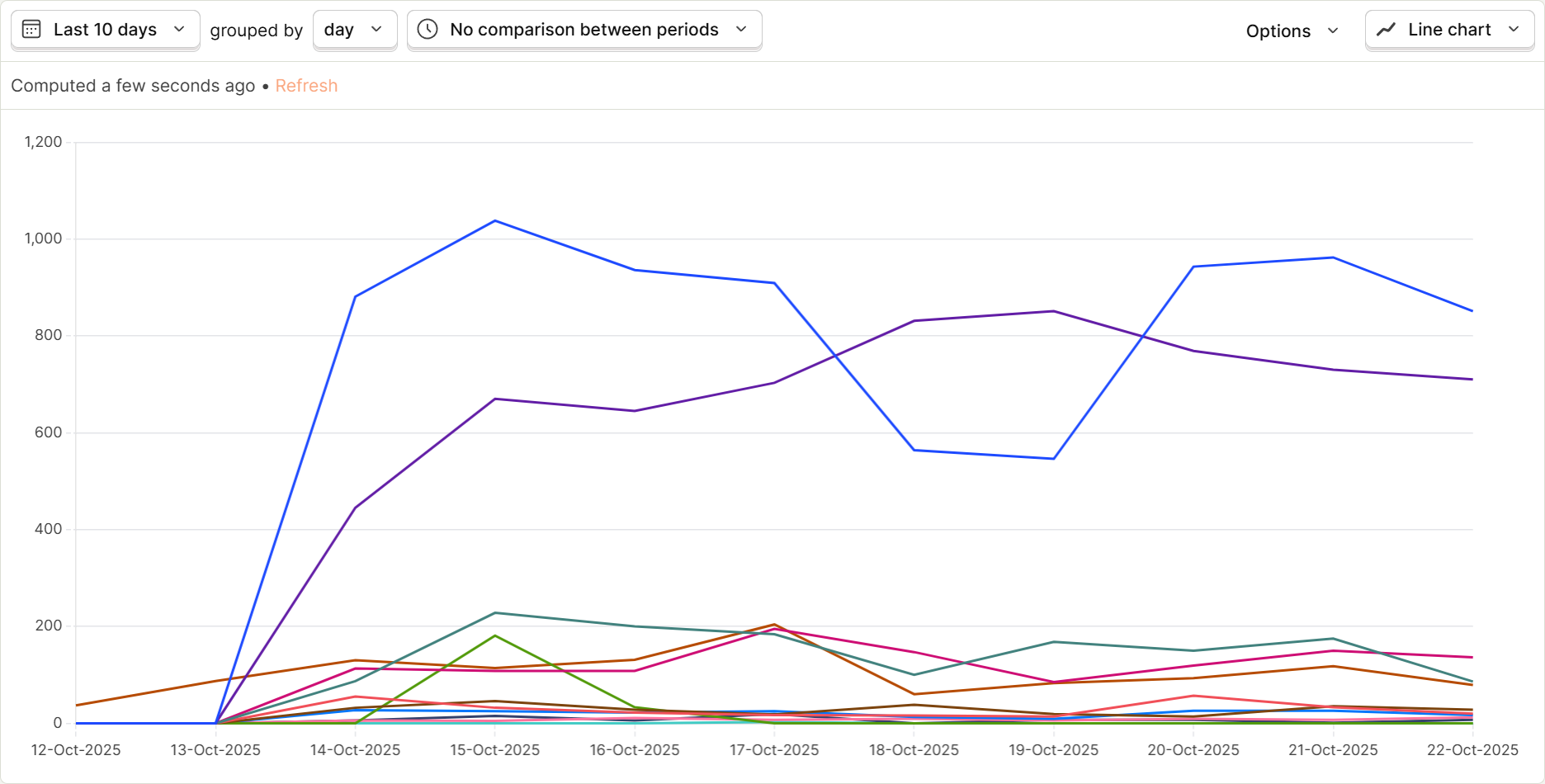
The brown line at the bottom that starts on Oct 12th represents
normalWhere is that traffic coming from? Here's the breakdown.
human pageviews. Everything else is AI traffic, each line representing a different bot and provider.A few important things to notice here;
- GooglebotStandard Google search index crawler.
- Crawler (search)
How much of that traffic is to my traditional analytics tools?
Bots which do not execute JavaScript, and which do not load referenced files like pixels won't be detected by traditional analytics like GA4.
However that does appear to be changing.
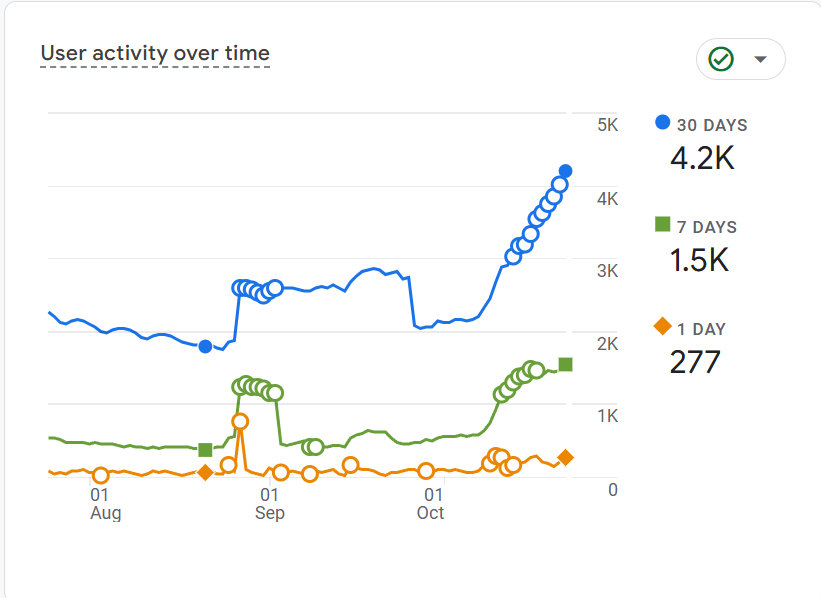
Here are Sygnal's 2024 GA4 user activity patterns from Jan - Dec 2024. They're fairly smooth, and organically tied to seasons, weather and weekly traffic cycles- just like humans are.

Here's the same report for this site for roughly the past 3 months.
Now this is interesting. I asked ChatGPT to analyze the table and to tell me what it could about each of the bots I'm seeing.
Here's what it reported.
OpenAI (ChatGPT-related)
ProviderWhat It IsPurposeType
ChatGPT User AgentTriggered when a
10 days ago I set up a reverse proxy on Sygnal's site to log all AI traffic it could identify.
Assistant (human-triggered)
And show up, it did. How much AI traffic is going directly to the HTML pages on my Webflow site? Far more than I expected.
How much AI traffic is going directly to the HTML pages on my Webflow site? Far more than I expected.
Crawler (AI training)
openai-search
The brown line at the bottom that starts on Oct 12th represents
normalWhere is that traffic coming from? Here's the breakdown.
human pageviews. Everything else is AI traffic, each line representing a different bot and provider.Crawler (search, RAG)
Microsoft (Bing + ChatGPT integration)General Search IndexersbingbotGooglegooglebot, duckduckbot🤖 AI Training Crawlersopenai-gptPerplexity AIperplexity-bot, commoncrawl-ccbot📚 AI Retrieval/Search (RAG) Botsopenai-search, likely used directly for query-time data👤 User-Agent AI Requests (human-triggered)openai-chatgpt-user, perplexity-user, google-user-fetchers-google🛠️ Service-specific Crawlersgoogle-special-crawlers
ProviderWhat It IsPurposeType
normalWhere is that traffic coming from? Here's the breakdown.
Where is that traffic coming from? Here's the breakdown.
Crawler (search engine index)
ProviderWhat It IsPurposeType
google-googlebot
GooglebotStandard Google search index crawler.How much of that traffic is to my traditional analytics tools? invisibleThis is difficult to answer, but the broad answer is "most of it."
invisibleThis is difficult to answer, but the broad answer is "most of it."
Google "user-triggered fetchers"Usually fired by features like Google Web Preview, Lighthouse testing, or Google-generated link fetches due to user actions.
Crawler (on-demand fetch)
google-special-crawlers
Google special-purpose crawlersUsed by specific services e.g. Google AdsBot, Google-Image, Google-Site-Verification, etc.
Crawler (service-specific)
PerplexityBotCrawls content to power Perplexity AI's large-language-model search engine.
perplexity-user
Perplexity User-TriggeredRepresents real user queries executed via Perplexity's assistant interface (like ChatGPT's browsing).
Assistant (human-triggered)
DuckDuckGo + AI Search
ProviderWhat It IsPurposeType
duckduckgo-botDuckDuckBotGeneral DuckDuckGo search crawler. Likely now feeding DuckDuckGo's AI summaries.Crawler (search/AI)
Common Crawl (used by many AI models)
ProviderWhat It IsPurposeTypecommoncrawl-ccbotCCBotCollects massive open web datasets used for AI training (OpenAI, Meta, AWS Bedrock, etc. use Common Crawl).Crawler (AI dataset provider)
Summary by Usage Category
Microsoft (Bing + ChatGPT integration)General Search IndexersbingbotGooglegooglebot, duckduckbot🤖 AI Training Crawlersopenai-gptPerplexity AIperplexity-bot, commoncrawl-ccbot📚 AI Retrieval/Search (RAG) Botsopenai-search, likely used directly for query-time data👤 User-Agent AI Requests (human-triggered)openai-chatgpt-user, perplexity-user, google-user-fetchers-google🛠️ Service-specific Crawlersgoogle-special-crawlers
Googlegooglebot, duckduckbot🤖 AI Training Crawlersopenai-gptPerplexity AIperplexity-bot, commoncrawl-ccbot📚 AI Retrieval/Search (RAG) Botsopenai-search, likely used directly for query-time data👤 User-Agent AI Requests (human-triggered)openai-chatgpt-user, perplexity-user, google-user-fetchers-google🛠️ Service-specific Crawlersgoogle-special-crawlers
Perplexity AIperplexity-bot, commoncrawl-ccbot📚 AI Retrieval/Search (RAG) Botsopenai-search, likely used directly for query-time data👤 User-Agent AI Requests (human-triggered)openai-chatgpt-user, perplexity-user, google-user-fetchers-google🛠️ Service-specific Crawlersgoogle-special-crawlers
- Assistant-type (human-triggered) requests usually reflect real user intent and are valuable.
- Crawler-type (AI training or indexing) may be fine, but you may want to:
What I've Learned
AIO is here, and it's probably all that matters now.
I'm not giving up on SEO just yet, but in my opinion, technical SEO is likely to be a wasted of effort. LLMs don't need JSON-LD or META tags to understand and use your content.
Page titles, paths, and headings probably matter- but more for Google's benefit. Having your site appear in search engines will still have value in 2026, mostly because LLMs will look there as well during assistant searches.
Traditional Analytics like GA4 are rapidly losing value
Unless AI bots start running JavaScript, using cookies, downloading full page content, they'll be invisible to client-side analytics pixels.
Even if that did happen, bots aren't likely to discover or navigate a site like user sill because they have a billion bookmarks that take them straight to the content they want... which means traffic flow analytics and funnels are broken.
The lack of mouse movements, scroll distance, click events, means session recordings are becoming less useful.
Bots are not the same
Even bots within our contrived "Assistant" category behave very differently in terms of how they use and convey your information- which means they're not directly 1:1 comparable to pageviews.
Traffic measurement needs a serious rethink
Sessions and user flows are now useless, because AI bots don't approach your site in the same way... and it's likely they don't use cookies at all.
Conversion approach needs a serious rethink
Customer-acquisition funnels are probably dead for the same reason- it's not how customer will discover, evaluate, or decide on your product. The LLM becomes the funnel, and you have a lot less control there.
Upsell funnels are still 100% strong because once you have the customer's details, you can contact them directly without LLM interference.
Rethinking the Approach
Currently I'm thinking that a more useful analysis would fall along two lines;
Attention ( aka signal strength )
Historically, someone saw your page, or they didn't. Attention was binary- they got 0% of your signal, or 100%.
And if I read my above traffic report with that mentality, I see this.
Which would suck.
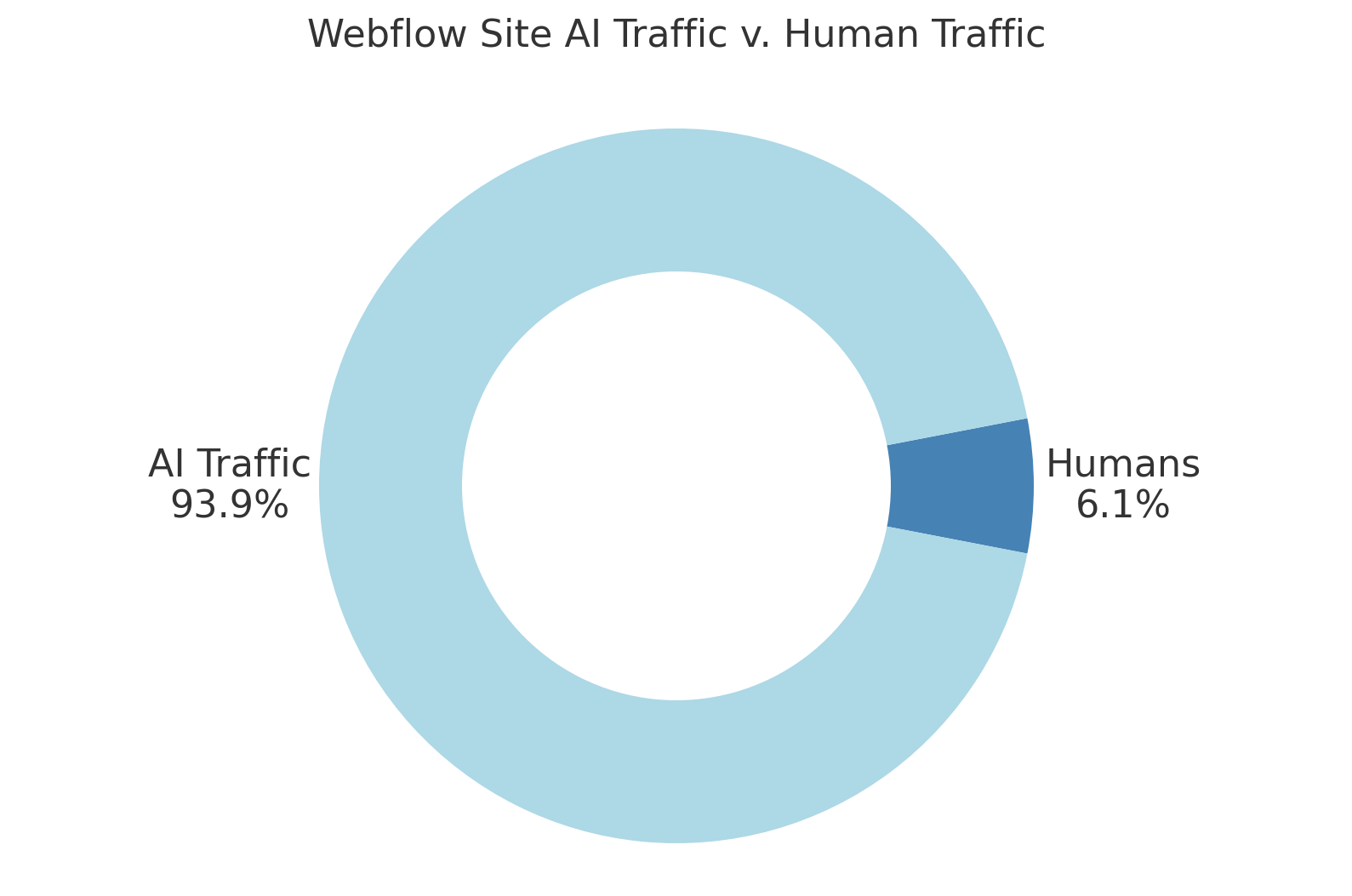
But that's not accurate, because a good portion of that AI traffic human proximate. A person was nearby, and was delivered my information, hopefully with fewer typos.
Let's assume ChatGPT described assistant bots accurately. That means that my signal strength isn't limited to the 1.136 page views this week. It also includes the assistant AI traffic, another 7,898 page views.
Let's take that idea further...
Now that AI's filter and meld your content in multiple ways, signal strength depends on the context in which it was delivered.
Signal strengthNotesModel1% - 10%Occurs when your information has been fully absorbed into the model, and blended with 1,000's of other sources. Since models are expensive to build, your information can be a year or more out of date as well. RAG20% - 70%Occurs when the LLM performs realtime research, usually by querying Google, and finds and parses your site in realtime. The information is current, but it will be integrated into a response with other sources as well. Assistant80% - 100%Some browsers like Bing and OpenAI's new browser seem to be operating as "augmented search" Your content might be diluted or interspersed with other content but it still takes a front-stage role in the response. Link100%Occurs when the LLM response includes a link directly to your site. Of course, that link must be current, not 404, and the user must click it.
I like this perspective. It feels better aligned with today's reality.
Engagement ( conversions )
The end goal is still key. But we have new challenges.
Does the user buy? Do they register? Do they learn? Do they like & follow?
The challenge now is that we lose visibility into that path, and have a lot less control over how information, branding, and value proposition are presented.
/If a user is trying to solve X, or find product Y using an LLM, new questions arise.
- Discovery - Were they made aware of our product / service
- Presentation - How was it presented alongside other options? Was it presented positively or negatively?
- Evaluation - Did the LLM "sell" it well as a viable solution and give the correct, critical decision
- Decision - What did the decision come down to as the user narrowed their choices and selected or abandoned your offering.
- Action - Then what? Was a link provided? Which link? How does the user convert?
- CRO - When we get a conversion, how do we trace the path back to the beginning? At this point, it's fairly opaque.
A New Spin on an Old Problem
If you're seeing this the same way I am, it's the same problem that broadcasters had when they released new TV shows. "Is anyone watching this?" was a multimillion-dollar question for every show, and every commercial.
Companies like AC Nielsen stepped in to fill that gap by building track & measure systems at the consumer end, to monitor and record consumer behavior. They reported, and sold- the who, the what, and the when.
I think soon enough, we'll see that here too- probably in the form of AI companies themselves using the free services to capture user data, and monitor and track their interactions all the way through to a sale or conversion event. Then sell that data back to large companies and ad agencies.
Instead of digging through analytics and looking at recorded sessions, you'll be reading anonymous, redacted LLM discussions where someone was trying to decide on the right new phone to buy.
Interesting times ahead, I guess.
Current Stats
The last 90 days...